Gem KafkaClient & Jkafka
该文档介绍zhe800_zhaoshang,tao800_fire 项目中使用到的gem KafkaClient 和 Jkafka
阅读文档,你将了解:
Kafka是什么?
kafka简介
Apache Kafka™ is a distributed streaming platform[1]
NOTE: 核心功能:
- 它让你发布和订阅数据流.
- 它让你具有很强容灾性的存储数据流.
- 它让你及时的处理数据流.
kafka基本原理与结构
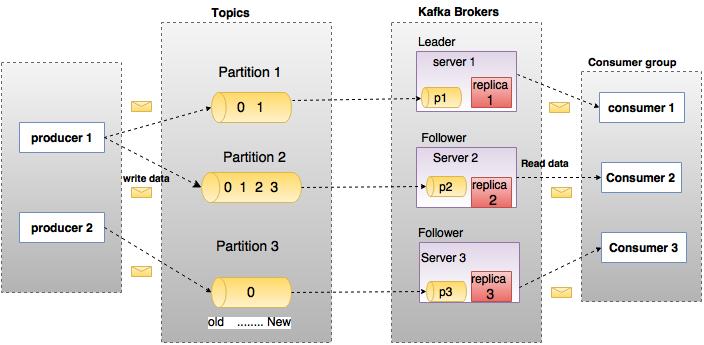
基础概念
| Components | Description |
|---|---|
| Topics | A stream of messages belonging to a particular category is called a topic. Data is stored in topics. |
| Partition | <p>Topics are split into partitions. For each topic, Kafka keeps a mini-mum of one partition. Each such partition contains messages in an immutable ordered sequence. A partition is implemented as a set of segment files of equal sizes.</p><p>Topics may have many partitions, so it can handle an arbitrary amount of data.</p> |
| Partition offset | Each partitioned message has a unique sequence id called as “offset”. |
| Replicas of partition | Replicas are nothing but “backups” of a partition. Replicas are never read or write data. They are used to prevent data loss. |
| Brokers | <p>i) Brokers are simple system responsible for maintaining the pub- lished data. Each broker may have zero or more partitions per topic. Assume, if there are N partitions in a topic and N number of brokers, each broker will have one partition.</p> <p>ii) Assume if there are N partitions in a topic and more than N brokers (n + m), the first N broker will have one partition and the next M broker will not have any partition for that particular topic.</p> <p> iii) Assume if there are N partitions in a topic and less than N brokers (n-m), each broker will have one or more partition sharing among them. This scenario is not recommended due to unequal load distri- bution among the broker.</p> |
| Kafka Cluster | Kafka’s having more than one broker are called as Kafka cluster. A Kafka cluster can be expanded without downtime. These clusters are used to manage the persistence and replication of message data. |
| Producers | Producers are the publisher of messages to one or more Kafka topics. Producers send data to Kafka brokers. Every time a producer pub- lishes a message to a broker, the broker simply appends the message to the last segment file. Actually, the message will be appended to a partition. Producer can also send messages to a partition of their choice. |
| Consumers | Consumers read data from brokers. Consumers subscribes to one or more topics and consume published messages by pulling data from the brokers. |
| Leader | “Leader” is the node responsible for all reads and writes for the given partition. Every partition has one server acting as a leader. |
| Follower | Node which follows leader instructions are called as follower. If the leader fails, one of the follower will automatically become the new leader. A follower acts as normal consumer, pulls messages and up- dates its own data store. |
Kafka Cluster
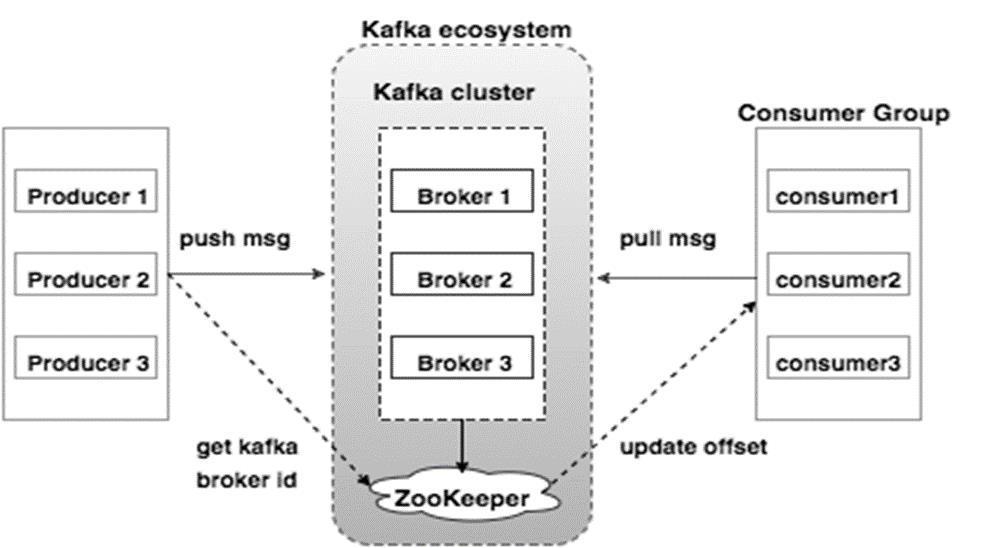
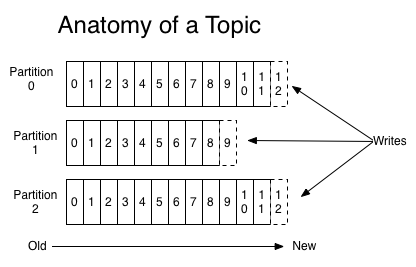
Topic and Logs
a Distributed Messaging System for Log Processing
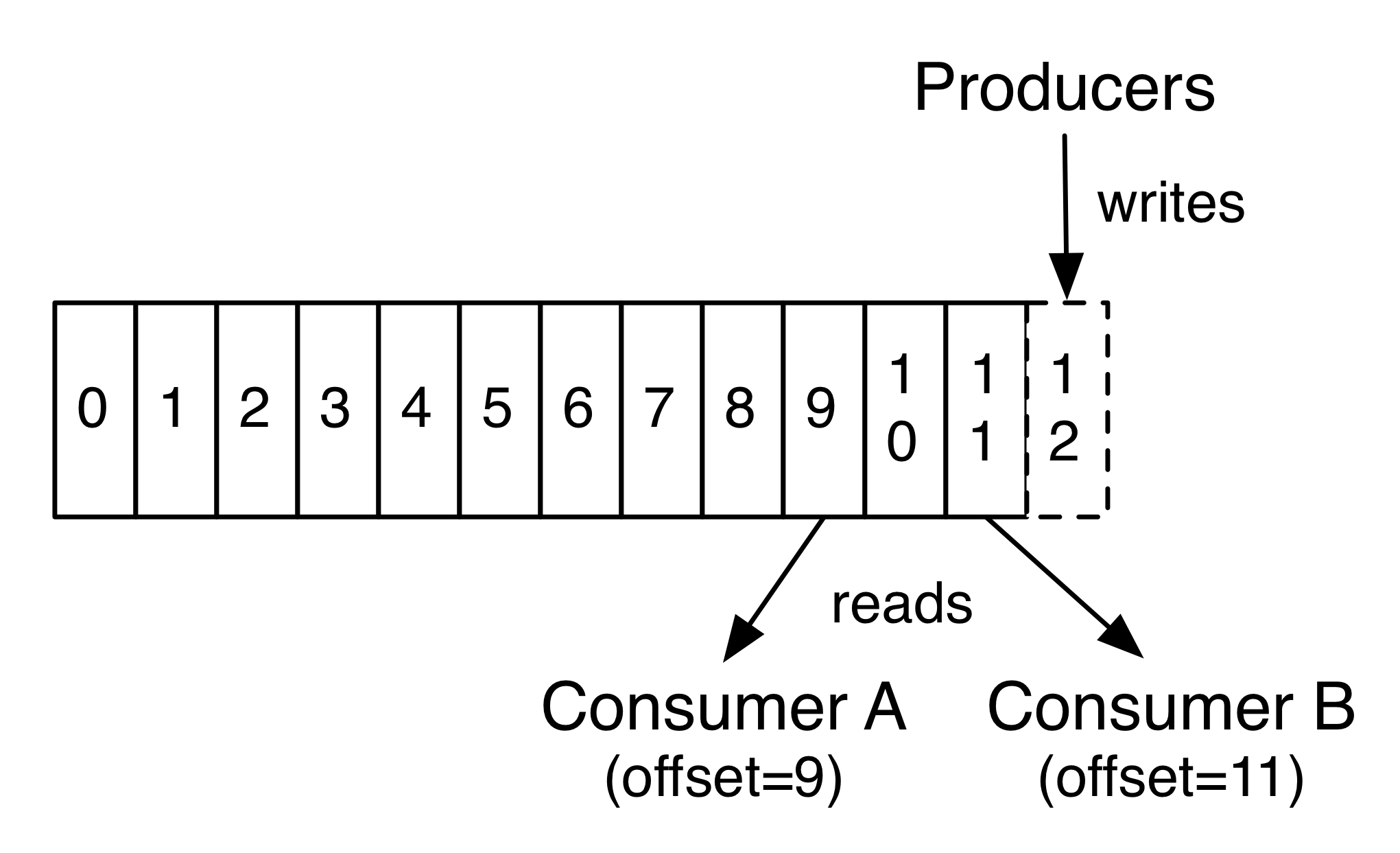
Consumer and Consumer-Group
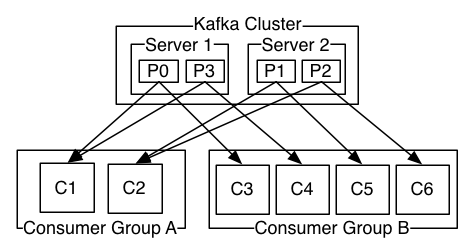
kafka的使用
gem poseidon
发送消息
broker = KafkaClient.configuration['borkers'].split
require 'poseidon'
producer = Poseidon::Producer.new(broker, "my_test_producer")
messages = []
messages << Poseidon::MessageToSend.new("topic6", "#{Time.now}")
producer.send_messages(messages)
接收消息
broker = KafkaClient.configuration['borkers'].split
require 'poseidon'
consumer = Poseidon::ConsumerGroup.new("poseidon_group_name_4", broker, [KafkaClient.configuration['zookeepers'].split.first], "topic6", {})
consumer.fetch_loop do |partition, messages|
messages.each do |m|
have_retried = false
value_utf8 = m.value.force_encoding('utf-8')
puts "value: #{m.value}, offset: #{m.offset}, partition: #{partition}"
time = m.value.split(",").first
if time.present?
puts "消费时间: #{Time.now - time.to_time}s\n"
end
end
end
gem ruby-kafka
发送消息
require "kafka"
brokers = ["kafka-cluster2.base.svc.zhe800.local:9092"]
kafka = Kafka.new(seed_brokers: brokers, client_id: "my-application")
kafka.deliver_message("#{Time.now}", topic: "greetings")
接收消息
require "kafka"
brokers = ["kafka-cluster2.base.svc.zhe800.local:9092"]
kafka = Kafka.new(seed_brokers: brokers)
group_id = "my-consumer"
consumer = kafka.consumer(group_id: group_id)
topic = "greetings"
consumer.subscribe(topic)
consumer.each_message do |message|
puts "topic:#{message.topic}, partition:#{message.partition}, offset:#{message.offset}, key:#{message.key}, value:#{message.value}"
if message.value.to_time.present?
puts "消费时间:#{Time.now - message.value.to_time}s\n"
end
end
poseidon和ruby-kafka的区别
NOTE:
- offset 存储方式不同: poseidon 使用zookeeper来记录消费过的offset, ruby-kafka消费的offset存储在 Kafka 的Topic:” __consumer_offsets”中
利用 Kafka 自身的 Topic,以消费的Group,Topic,以及Partition做为组合 Key。所有的消费offset都提交写入到上述的Topic中。因为这部分消息是非常重要,以至于是不能容忍丢数据的,所以消息的 acking 级别设置为了 -1,生产者等到所有的 ISR 都收到消息后才会得到 ack(数据安全性极好,当然,其速度会有所影响)。所以 Kafka 又在内存中维护了一个关于 Group,Topic 和 Partition 的三元组来维护最新的 offset 信息,消费者获取最新的offset的时候会直接从内存中获取。 消费者需要频繁的去与 Zookeeper 进行交互,而利用ZKClient的API操作Zookeeper频繁的Write其本身就是一个比较低效的Action,对于后期水平扩展也是一个比较头疼的问题。如果期间 Zookeeper 集群发生变化,那 Kafka 集群的吞吐量也跟着受影响。[2]
- kafka版本不同
ruby-kafka: Although parts of this library work with Kafka 0.8 – specifically, the Producer API – it’s being tested and developed against Kafka 0.9. The Consumer API is Kafka 0.9+ only.[3] poseidon: Poseidon is a Kafka client. Poseidon only supports the 0.8 API and above.[4]
- poseidon作者推荐使用ruby-kafka
This project is currently unmaintained. There are a handful of other options for interacting with Kafka from Ruby:A pure ruby client, ruby-kafka, which is 0.9 compatible and support consumer groups.
KafkaClient介绍与使用
INFO: 项目地址
git clone /ruby_gem_kafka_client.git
KafkaClient 简介
NOTE:
KafkaClient是基于[Poseidon][poseidon]和[PoseidonCluster][poseidon_cluster]封装的一个在ruby on rails环境上,同时具有consumer和producer的gem. [poseidon]: https://github.com/bpot/poseidon [poseidon_cluster]: https://github.com/bsm/poseidon_cluster
安装
gem install kafka_client
用法和文档
基本用法
安装好gem之后,执行命令
rails g kafka_client
会生成rails项目中生成如下目录结构:
app/
kafkas/
consumers/
example_consumer.rb
producers/
example_producer.rb
config/
kafka.yml
配置
NOTE: kafka的配置都在config/kafka.yml文件里
- 由于kafka需要broker等配置,所以需要在配置文件中配置自己的brokers和client_id等信息.
- 其中该gem接入了elklogger来做额外的log输出,elklogger是为了输出egoeye接受的log来在页面上看到日志输出的工具
- 如需输出elklogger格式的log,则必须下载和安装ElkLogger的Gem,并且在配置文件里配置use_elk_logger: true
- consume_retry_times consumer消费消息时,会捕获offsite range out异常 该项配置为 < = 0, 不retry, 发生错误直接raise 该项配置为 > 0, 最多retry n 次
如何书写一个producer
class ExampleProducer
include KafkaClient::Producer
end
# 调用
msg = { test_message: 'hello world' }.to_json
topic = 'test_topic'
ExampleProducer.send_kafka_messages(msg, topic)
由于kafka有分布式,所以会导致消息不是序列的,那么就要把一个消息推送到一个broker上,一个broker只会被一个消费者消费,那么就实现了有序功能
msg = { test_message: 'hello world' }.to_json
topic = 'test_topic'
key = '1'
ExampleProducer.send_kafka_message_with_key(topic, msg, key)
如何书写一个consumer
class ExampleConsumer
include KafkaClient::Consumer
##
# ==== Description
# consumer的handle_messages方法是一个fetch_loop循环,监控着队列的消耗,
# 如果一个队列连续7天没有消息,那么这个方法就会停止监控,开发者可以考虑用第三方来监控实现重启
#
def self.handle_test_topic_message
topic = 'test_topic'
# 这里new的时候支持Poseidon传参数,比如: self.new("topic_name", trail: true)
# 具体获取策略可参考poseidon的用法
consumer = self.new(topic)
consumer.handle_messages do |partition, message|
puts message
end
end
end
#调用
ExampleConsumer.handle_test_topic_message
用户可以具体参考example_consumer.rb 和 example_producer.rb 书写自己的consumer和producer
log的输出
consumer启动的日志在
log/kafka_consumer.#{Rails.env}.log
每个consumer有自己的log日志,格式为:log/kafka_messages_#{consumer_name}_ruby.#{Rails.env}.log, 如生成的example_consumer.rb则对应的log文件为:
log/kafka_messages_consumers_example_consumer_ruby.#{Rails.env}.log
注意事项及扩展
覆写Kafka::ExportException.export方法
rake启动的log和消费消息的log都是写入到log文件里的,如果想把错误抛出来放到第一个第三方的软件上,比如newrelic,那么可以覆写Kafka::ExportException.export方法,例如
#在config/initializers/kafka_client.rb
module KafkaClient
module ExportException
##
# ==== Description
# 覆写该方法,抛入到newrelic中
##
def self.export(exception)
NewRelic::Agent.notice_error(exception)
end
end
end
Jkafka介绍与使用;
Jkafka 介绍
Jkafka是基于Rails Engine封装的一个在ruby on rails环境上的一个gem,作为kafkaClient的依赖,在项目中引用。或者作为gem直接引用在项目中。kafka的消费方式从kafka cluster上获取后消费消息的形式,改为请求方从zookeeper上抓取未消费的信息后,将调用http接口,并项目中对应的kafka consumer,进行消费。
安装
gem install jkafka
用法和文档
基本用法
安装好gem后,在引用该gem的项目的config/routes.rb文件中,添加:
mount Jkafka::Engine => "/jkafka"
发post请求URL:”域名/jkafka/java_kafka_http” 参数:
{
topic: 'topic', # kafka consumer 对应的topic
consumer_group_name: 'group_name', # kafka consumer对应的消费组名称
partition: '1', # consumer partition
offset: '134', # consumer offset
message_value: 'message_value' #JSON数据
}
返回结果:
{
101 => "未找到当前的consumer!",
102 => "处理过程异常!",
200 => "处理成功!"
}
For example:
INFO:
- 将该consumer在god中移除, 不再直接从zookeeper上获取消息
- 请求方监控该consumer的数据,并调用接口,传入参数,进行消费
Test:
起一个rails console
options = {
topic: 'zhaoshang_deal_base',
group_name: 'consumers_picture_deal_check_ruby',
partition: '1',
offset: '134',
message_value: 'message_value'
}
RestClient.post 'http://zhaoshang.zhe800.com:3025/jkafka/java_kafka_http/consume_kafka_messages', options
log的输出
INFO: 每一个调用的请求参数都会记录在这个日志中
log/kafka_messages_consume.log.elk
参考资料: [1]:http://kafka.apache.org/intro “kafka官方文档” [2]:http://www.cnblogs.com/smartloli/p/6266453.html “原文链接” [3]:https://github.com/zendesk/ruby-kafka#ruby-kafka [4]:https://github.com/bpot/poseidon#unmaintained
- Kafka: a Distributed Messaging System for Log Processing点击这里下载
- apache_kafka_tutorial点击这里下载
- Poseidongit项目地址点击这里
- Ruby-kafka项目地址点击这里
- ruby_gem_ kafka_client项目地址点击这里
- Kafka: a Distributed Messaging System for Log Processing点击这里下载
- apache_kafka_tutorial点击这里下载
- Poseidongit项目地址点击这里
- Ruby-kafka项目地址点击这里
- ruby_gem_ kafka_client项目地址点击这里
- 创建一个rails engine:点击这里
- rails guides中的rails engine: 点击这里
