面试总结2 - 用户访问鉴权流程(头条二面)
2019年4月11日,本人去头条广告部门面试研发,首先公司给我的氛围略显压抑,或许以后很难再遇到招商ruby这么好的部门了吧。
不过技术上还是很强的,在总结写下这篇博文时一些东西豁然开朗。
总结来说,一面技术面,基础知识 + 算法题,应该算easy;
不想栽在了二面项目面,面试官是一个毛脸大叔,应该是个技术大牛,直到写下此篇总结流程时,才明白大叔真正要问的是什么。
骚年仍需努力哈!
1 总结前的话
二面没有问业务流,而是问了用户访问鉴权。
我的大致描述:
用户业务访问是在ruby服务上,然后每次访问之前都是要访问一下java鉴权服务,传递浏览器的cookie获取权限结果。
然后面试官问到的问题有:
- 黑客盗用cookie一直攻击怎么办?
- 黑客一直攻击rpc调用怎么办?
- ruby如何找到java的服务的?
当时觉得有些莫名其妙,觉得问题都是啥子哟,惭愧惭愧!
我猜测之所以业务流等问题不问,是因为都是纯业务实现,虽有涉及一些技术点,但总归不好拓展。
而用户鉴权访问面试官的目的是问我一个完整的网络安全访问过程。
其中包括不限于http访问过程(TCP/IP)、网络完全(http/https)、RPC(TCP、IP)、访问资源响应等等。
这是一个完整的计算机网络知识系统,而鄙人眼光真是太局限了。
2 用户鉴权业务逻辑以及计算机网络流程
用户访问过程: 用户业务访问是在ruby服务上,然后每次访问之前都是要访问一下java鉴权服务,传递浏览器的cookie获取权限结果。
计算机网络视角:
用户浏览器 –> ruby服务器 –> java服务器 –> ruby服务器 –> 反馈用户
- 用户发出http/https请求;
- ruby服务器收到请求,将用户cookie发送给java
- java鉴权
- ruby分析鉴权结果
- 鉴权通过,将用户逻辑处理结果反馈回去; 否则提示用户权限信息;
那么主要包含两块问题:
- 本地http访问服务器
- 服务器响应http请求
而在计算机网络的基础上,最主要是的网络完全和黑客攻击问题,整个流程 + 安全的技术难点才是一个完整的知识体系面试过程。
3 用户访问服务器
主要包括用户浏览器发出请求,到服务器收到用户请求的过程。
此部分主要是计算机网络基础知识,数据层 + TCP协议 + nginx等;
1 一次完整的HTTP请求过程
当我们在web浏览器的地址栏中输入: www.baidu.com,然后回车,到底发生了什么
总结:
域名解析 –> 发起TCP的3次握手 –> 建立TCP连接后发起http请求 –> 服务器响应http请求,浏览器得到html代码 –> 浏览器解析html代码,并请求html代码中的资源(如js、css、图片等) –> 浏览器对页面进行渲染呈现给用户
1 过程概览
1.对www.baidu.com这个网址进行DNS域名解析,得到对应的IP地址
2.根据这个IP,找到对应的服务器,发起TCP的三次握手
3.建立TCP连接后发起HTTP请求
4.服务器响应HTTP请求,浏览器得到html代码
5.浏览器解析html代码,并请求html代码中的资源(如js、css图片等)(先得到html代码,才能去找这些资源)
6.浏览器对页面进行渲染呈现给用户
2 nginx过程概览
nginx是一个反向代理服务器,首先要明确的是nginx是一个服务器,服务器本身ok。
1 nginx概述
Nginx事件框架主要是针对传输层的TCP的,作为Web服务器HTTP模块需要处理的则是HTTP
2 DNS域名解析
1 作用
DNS解析: 将域名解析为ip地址
2 解析过程
DNS域名解析采用的是递归查询的方式,过程是:先去找DNS缓存->缓存找不到就去找根域名服务器->根域名又会去找下一级,这样递归查找之后,找到了,给我们的web浏览器
递归过程:
- 首先会搜索浏览器自身的DNS缓存(缓存时间比较短,大概只有1分钟,且只能容纳1000条缓存)
- 如果浏览器自身的缓存里面没有找到,那么浏览器会搜索系统自身的DNS缓存
- 如果还没有找到,那么尝试从本地hosts文件里面去找
- 在前面三个过程都没获取到的情况下,就递归地去域名服务器去查找,具体过程如图。(本地DNS服务器一般都是你的网络接入服务器商提供,比如电信,移动)
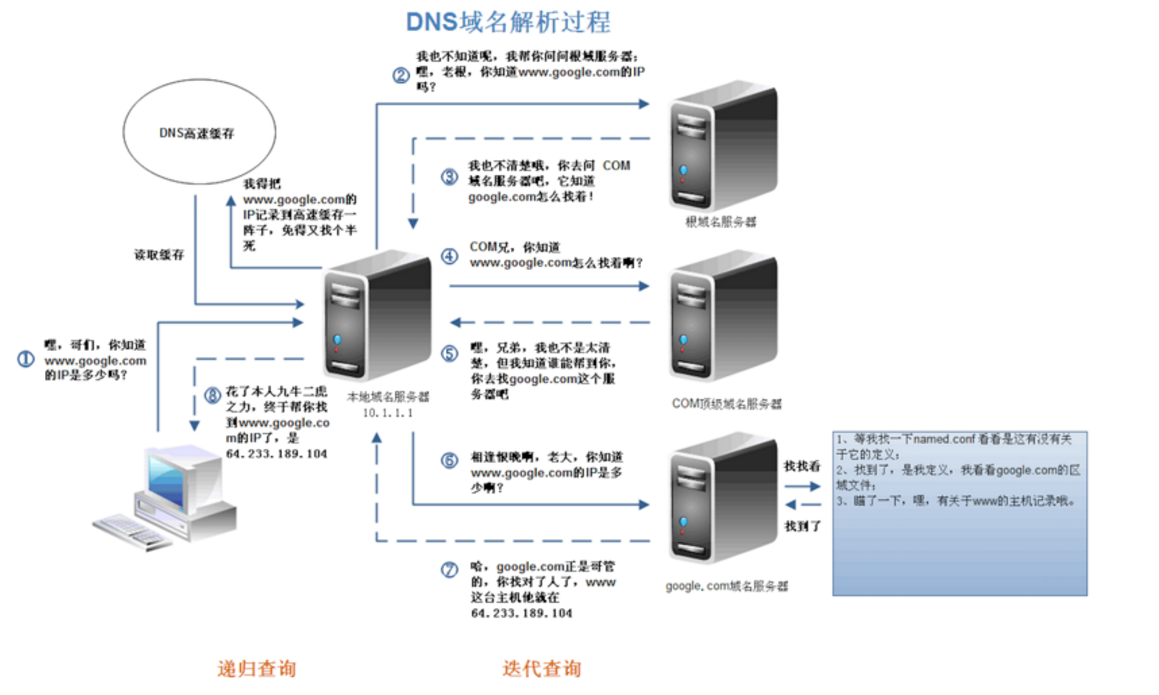
1. 从本地缓存获取的ip地址会被标记为非权威服务器的应答。
2. 本地缓存无则请求DNS根服务器进行查询。会从配置文件里面读取13个根域名服务器(全世界13个,名字A-M)的地址,然后向其中一台发起请求。
3. 根DNS服务器拿到这个请求后,告诉本地DNS服务器,你可以到域服务器(com/net/cn等)上去继续查询,并给出域服务器的地址,这种过程是迭代过程并不是递归过程。
4. 然后本地DNS服务器继续向域服务器发出请求。
以.com域服务器为例:
一句话: .com域服务器再返回一个域名解析服务器的地址。
.com域服务器收到请求之后,也不会直接返回域名和IP地址的对应关系,而是告诉本地DNS服务器,你的域名的解析服务器的地址。
(比如,com域的服务器发现你这请求是baidu.com这个域的,一查发现了这个域的NS(name server),那我就返回给你,你再去查。)
4.最后,本地DNS服务器向域名的解析服务器发出请求,这时就能收到一个域名和IP地址对应关系。
本地DNS服务器把IP地址返回给用户电脑,并把这个对应关系保存在缓存中,以备下次别的用户查询时,可以直接返回结果,加快网络访问。
(比如,向baidu.com这个域的权威服务器发起请求,baidu.com收到之后,查了下有www的这台主机,就把这个IP返回给你了,然后ISPDNS拿到了之后,将其返回给了客户端,并且把这个保存在高速缓存中。)
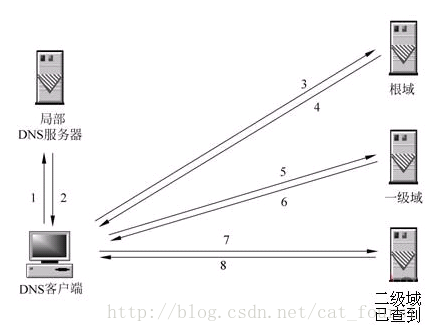
总结:所以DNS查询有递归和迭代两种方式
1 递归查询

2 迭代查询
域名

3 DNS优化(DNS缓存、DNS负载均衡)
1 DNS缓存
了解了DNS的过程,如果每次都经过这么多步骤,是否太耗时间?如何减少该过程的步骤呢?
那就需要DNS优化了——DNS缓存
DNS存在着多级缓存,从离浏览器的距离排序的话,有以下几种: 浏览器缓存,系统缓存,路由器缓存,IPS服务器缓存,根域名服务器缓存,顶级域名服务器缓存,主域名服务器缓存。
在你的chrome浏览器中输入:chrome://dns/,你可以看到chrome浏览器的DNS缓存。
系统缓存主要存在/etc/hosts(Linux系统)中:
2 DNS负载均衡 同一个主机多个ip
互联网用户巨大的今天,假如亿万请求请求的资源都位于同一台机器上面,那么这台机器随时可能会崩掉。
处理办法就是用DNS负载均衡技术,它的原理是在DNS服务器中为同一个主机名配置多个IP地址, 在应答DNS查询时,DNS服务器对每个查询将以DNS文件中主机记录的IP地址按顺序返回不同的解析结果, 将客户端的访问引导到不同的机器上去,使得不同的客户端访问不同的服务器,从而达到负载均衡的目的。 例如可以根据每台机器的负载量,该机器离用户地理位置的距离等等。
大家耳熟能详的CDN(Content Delivery Network)就是利用DNS的重定向技术,DNS服务器会返回一个跟用户最接近的点的IP地址给用户,CDN节点的服务器负责响应用户的请求,提供所需的内容。
3 TCP协议
此处最好还要学习一下网络分层
TCP/IP协议主要记忆每次发送的内容以及所处的状态 TCP
4 发起 HTTP 请求
HTTP请求报文由三部分组成:请求行,请求头和请求正文
请求行:用于描述客户端的请求方式,请求的资源名称以及使用的HTTP协议的版本号(例:GET/books/java.html HTTP/1.1)
请求头:用于描述客户端请求哪台主机,以及客户端的一些环境信息等
注:这里提一个请求头 Connection,Connection设置为 keep-alive用于说明 客户端这边设置的是,本次HTTP请求之后并不需要关闭TCP连接,这样可以使下次HTTP请求使用相同的TCP通道,节省TCP建立连接的时间
请求正文:当使用POST, PUT等方法时,通常需要客户端向服务器传递数据。这些数据就储存在请求正文中(GET方式是保存在url地址后面,不会放到这里)
5 HTTP 响应
HTTP响应也由三部分组成:状态码,响应头和实体内容
状态码:状态码用于表示服务器对请求的处理结果
列举几种常见的:
200(没有问题)
302(要你去找别人)
304(要你去拿缓存)
307(要你去拿缓存)
403(有这个资源,但是没有访问权限)
404(服务器没有这个资源)
500(服务器这边有问题)
若干响应头:响应头用于描述服务器的基本信息,以及客户端如何处理数据
实体内容:服务器返回给客户端的数据
注:html资源文件应该不是通过 HTTP响应直接返回去的,应该是通过nginx通过io操作去拿到的吧
